|
 |
||||||||||||||||||||||||
|
| ||||||||||||||||||||||||
|
ユニークな手法で非重複化を行うData Domainのデータプロテクションストレージ【前編】 |
||||||||||||||||||||||||
|
|
||||||||||||||||||||||||
|
| ||||||||||||||||||||||||
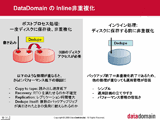
Data Domainの技術概要については本連載でもすでに取り上げているが(2006年3月27日付、「テープレス・バックアップを後押しするCOS(Capacity Optimized Storage)」)、脱稿後にData Domainの日本法人(データドメイン株式会社)が設立され、日本国内でも本格的にビジネスが展開されるようになった。そこで、技術や導入実績がさらに進んだ2008年末、データドメイン株式会社 シニアシステムズエンジニアの村山雅彦氏にData Domainの技術詳細と最新動向をお聞きしてきた。今回より2回にわたって、Data Domain製品を支えるアーキテクチャとその構成技術について解説していく。 ■ 従来型のディスクストレージでD2Dバックアップを実施するのは高コスト データバックアップは、例えば1日1回という典型的な頻度を想定すると、初日はフルバップアップによって起点となるデータを取得し、翌日からは日々の変更分だけを差分バックアップないしは増分バックアップで積み重ねていくという手順がとられる。バックアップウインドウの短縮を優先するなら前日からの変更分のみを取得する増分バックアップ、リストアのしやすさを優先するなら起点となる初日からの変更分を取得する差分バックアップが適している。筆者がこれまで多くのエンドユーザーを取材したところでは、迅速なリストアを重視した差分バックアップを採用する企業が圧倒的に多かった。もちろん、日々のバックアップウインドウ内でフルバックアップを確実に実行できるなら、毎日フルバックアップを実施すれば理想的といえよう。
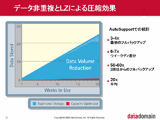
従って、例えばフルバックアップを10回繰り返したとすれば、10個の元データがそれぞれ2分の1に圧縮されたとしても、ディスクストレージに保管すべきデータは10個に増えている。つまり、トータルで見れば元データの5倍にも膨れあがる計算になるのだ。テープストレージではテープカートリッジの本数を増やせば済む話だが、ディスクストレージではHDDの台数を増やしたり、場合によってはコントローラを上位モデルに切り替えたりするなど、かなりのコストアップを余儀なくされてしまう。 ■ セグメントごとに生成したフィンガープリントによって重複判定を実行 このような中で登場したのが、非重複化または重複排除と呼ばれるデータ削減技術である(本稿では、非重複化という用語で統一する)。非重複化は、以前書かれたデータと重複するものを積極的に取り除き、まったく重複しないデータのみを新たに書き込む。従来のデータ圧縮技術はすべてのデータに対して一様に圧縮処理をかけるが、非重複化技術は2回目以降に書き込まれたデータに対して強く作用する。このため、通常のプライマリーストレージに使用しても効果は薄く、何世代ものデータを重ねて保管するバックアップやアーカイブ、ニアライン用途向けのセカンダリーストレージで威力を発揮する技術なのだ。Data Domainを例にとると、最初のフルバックアップ時には数倍程度の圧縮率にとどまるが、2回目からのフルバックアップでは50~60倍、平均すれば20倍もの圧縮効果が得られる。
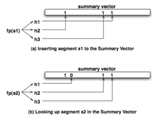
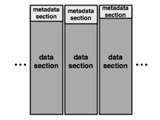
セグメントの重複判定は、ディスク上からセグメントをすべて読み出し、しらみつぶしに比較していく方法が最も簡単なのだが、大量のセグメントを単純に読み出していてはまったく実用にならない。そこで、非重複化技術では、セグメントそれぞれのアイデンティティを表すフィンガープリント(いわば指紋のような役割を果たすもの、以下FP)をハッシュ関数によって生成する。例えば、Data Domainではハッシュ関数のアルゴリズムとしてSHA-1を採用しており、セグメントそれぞれに対して160ビット長のFPが作られる。このFP群をデータベース化したFPインデックスを設け、FPインデックスの参照によってセグメントの重複判定を行う。4~12KBのセグメントではなく160ビットのFPによって重複判定が可能になるので、比較時に読み出すべきデータは大きく削減される。 ■ ディスクアクセスを前提とした重複判定ではスループットを高められない FPインデックスがすべてメモリー上に載るサイズであれば、インデックスの参照をスピーディーに行えるので重複判定のスループットも間違いなく向上する。しかし、大容量データに対するFPインデックスの総量は極めて大きい。例えば、80TBの実データを平均8KBのセグメントに分割した場合、これらのセグメントに対するFP値は総量で20GB(=80TB÷8KB×160バイト)にも達する。これほどの巨大なインデックスをメモリー上に載せることは現時点のシステムではコスト的に見合わない。このため、FPインデックスをディスク上に配置している製品がほとんどである。ここで、ディスク上のFPインデックスがどれくらいのスループットを見込めるか、実際に計算してみよう。セカンダリーストレージで多く使われているSATA HDDは、1台あたりのI/O性能がおおむね120回とされる。セグメントの平均サイズを8KBとすると、1秒あたりのスループットは約1MB/秒(≒8KB×120回)と算出される。このため、100MB/秒のスループットを得ようとすれば、HDDが100本も必要になる。SATA HDDは1本あたりの容量が非常に大きいことから、多数のHDDを搭載してしまうと必要以上に大きなディスク容量になってしまう。そもそも、HDDの台数を減らしてコストを削減するために非重複化技術を導入するわけなので、データ転送のスループットを高めるために多数のHDDを組み合わせなければならないとなると本末転倒なのだ。 「非重複化技術では、いかにHDD 1台あたりのスループットを高めるかが重要になります。そのためには、なるべくディスクアクセスに頼らない方法で重複判定を行う必要があります。Data Domainは、数学的なアルゴリズムを通じてCPUとメモリー上の計算だけで重複判定を行えるようなアーキテクチャを採用し、少ないHDD台数と高いスループットを両立しています。ここが、他社との絶対的な差別化ポイントになります。(村山氏)」 ■ 重複していないデータを超高速に判別するサマリーベクター Data Domainの非重複化技術で中核となるのは、サマリーベクター(summary vector)とローカリティープリフェッチング(locality prefetching)という2つの要素技術である。多くのストレージではFPインデックスをディスク上に配置していると述べたが、Data Domainのストレージ製品では、このFPインデックスに加え、インメモリーでの高速な重複判定手段としてサマリーベクターを併用している。
そして、再度データを書き込む際には、各セグメントのFP値に対する3つの値を計算すると、内容が重複している(と思われる)セグメントに対応するビット位置はすでにすべてが1となっている。これに対し、初めて書き込むセグメントに対応するビット位置には0が含まれている。このように、対応するビット位置が1か0かを見ることによって、即座に重複判定を行えるわけだ。いずれにせよ、サマリーベクター自身はメモリー上に置かれているものなので、CPUとメモリー上の計算のみで高速に重複判定を行える。 基本的に、対応する3つのビット位置のうち、どれか1つでも0が見つかればデータは絶対に重複していないことが保証される。しかし、3のビット位置がすべて1であっても、データが必ず重複していることは保証されない。実は、サマリーベクターのもとになるブルームフィルターは、原理的に偽陽性(false positive)による誤検出の可能性があり、誤って『重複している』と判断してしまうことがある。このため、サマリーベクターだけでは正確な重複判定を行うことはできず、最終的な判断はFPインデックスに委ねなければならない。とはいえ、少なくとも重複している可能性が高いセグメントのみがFPインデックスの参照対象となることから、他社の非重複化技術と比べればディスクアクセスはこの時点でもかなり削減される。 ■ 最終的な重複判定を高速化するローカリティープリフェッチング
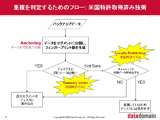
「Data Domainのアーキテクチャは、HDDの台数が少なくても、CPUの処理能力に比例してスループットが高まっていきます。シングルコアCPUの2年前には80MB/秒程度でしたが、デュアルコアCPUの1年前には160~180MB/秒、クアッドコアCPUの現在では300MB/秒にも達しています。今後、CPUのコア数が6コアや8コアに増えれば、さらにスループットが向上するでしょう。HDDは、容量こそ増え続けていきますが、I/O性能(1秒あたりのI/O数)はあまり向上しないと予想されます。このような中で、HDDの台数を増やすことなくスループットを高めていくには、Data Domainのようなアーキテクチャが圧倒的に有利なのです。(村山氏)」
後編では、Data Domain製品ならではの高度なデータ保護技術と災害対策(DR)に欠かせないレプリケーション機能について解説していく。 ■ URL データドメイン株式会社 http://www.datadomain.com/jp/ ■ 関連記事 ・ データドメイン、重複排除ストレージの最上位製品「DD690」(2008/10/02) ・ ユニークな手法で非重複化を行うData Domainのデータプロテクションストレージ【後編】(2009/01/30)
( 伊勢 雅英 )
|