 |
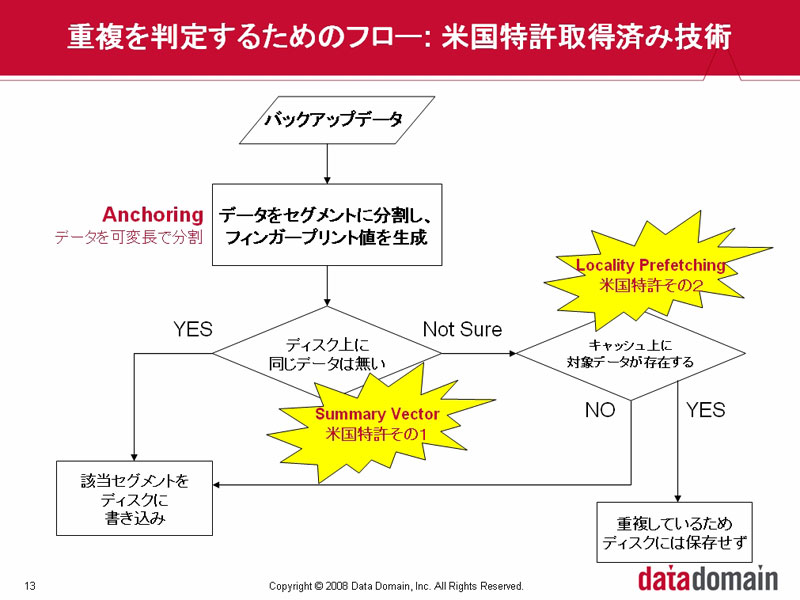
| Data Domain独自の重複判定フロー。他社のようにFP値を直接参照する方法では、HDDの台数を増やさなければスループットを確保できない。これに対し、Data Domainは、最初のふるいとしてサマリーベクターを使用し、絶対に重複していない部分と重複している可能性のある部分を切り分ける。そして、重複している可能性のある部分を、ローカリティープリフェッチングによって確実に切り分ける。ほとんどの重複判定をインメモリーで実行できることから、少ないHDD台数でも非常に高いスループットが得られる |
| Copyright (c) 2009 Impress Watch Corporation, an Impress Group company. All rights reserved. |